
If you’ve toyed with Large Language Models (LLMs) for more than five minutes, you’ve probably heard the rallying cry: “Use RAG!” (Retrieval-Augmented Generation, for the uninitiated). The promise? Combine fancy word-vomit machines—err, I mean, advanced generative models—with a dash of external knowledge, and voilà! Instant facts, minimal nonsense, no more “hallucinations.” In an ideal world, that’s exactly how it would go down.
But guess what? Real-world retrieval can be messy. And the moment your queries wander off the happy path, you’ll see RAG systems slip on semantic banana peels, produce contradictory or incomplete data, or get stuck in the dreaded chunk-chop fiasco. Let’s just say that the “golden retrieval pipeline” you read about in that slick blog post doesn’t always hold up once you toss in domain-specific jargon, ambiguous user requests, and “Please find the JSON snippet that references a budget from 2015, specifically table row 57.” (Yes, that was a real query from a friend’s PoC. It didn’t end well).
Seeing how broken these things can be is exactly what drove me to build a new product (and, yes, start a brand-new enterprise) that incorporates domain fine-tuned embeddings and reranking, multi-retrieval methods (vector plus lexical), ontology-based knowledge graph integration for multi-hop queries, and a continuous pipeline that retrains models when the domain changes. That, coupled with automated data cleansing and ingestion, content-aware chunking, domain-aware prompt and query rewriting, and built-in observability — and you’ve got a solution that actually meets real enterprise demands.
This editorial is my personal gripe session about the tech we call SoTA RAG—and why, ironically, I’m making it my life’s work (aka building a startup) to figure out how to do RAG without cursing at your logs every other hour. And for those of you who are about to close this tab, see knowledge2.ai for more details.
Preface
For everyone else not in Gen Z, yes, this post is long. And yes, it’s decidedly snarky. Why? Because if you’ve been rummaging around the internet for RAG “how-tos,” you’ve probably stumbled on a thousand academically polished blog posts, most of which are based on limited PoCs running on squeaky-clean, public data. Fun to read, but useless once you’re knee-deep in a real corporate environment with six different PDF formats, infinite acronyms, and domain jargon that would make a NASA engineer cringe.
I’ve engineered dozens of RAG solutions across various domains, and the sanitized approach you see in those “perfect pipeline” tutorials usually goes out the window the moment you feed it your actual data. You might as well try spackling a wall with mashed potatoes. That’s why this monster post exists: to tell you what really happens when your chunker meets your CFO’s 200-page compliance doc, or when your “just fine-tune the embeddings” plan collides with your timeline and budget, and you realize you need develop and operate a complex data labeling and MLOps platform. Great.
So, buckle up—this is the stuff most academic posts conveniently skip. And if it sounds a bit ranty, well, that’s because building real-world RAG will do that to you. Enjoy the ride.
The Retrieval Rabbit Hole: Good Luck Finding What You Actually Need
The whole point of RAG is finding the right external knowledge. If the retriever messes up, the rest is just lipstick on a pig. And boy, does it mess up.
Embeddings: Welcome to the Grand Canyon of Domain Gaps
Let’s start at the heart of it all: the embedding step. Everyone’s hooking up to these big, shiny embedding models, trained on billions of English sentences scraped from the web—and assuming domain context will magically appear. Then the system chokes on a question about your company’s internal acronym “SVRG” (which apparently stands for “Super Vital Reporting Guideline,” but could just as easily mean “Stochastic Variance Reduced Gradient” to the generic model).
- Generic vs. Domain-Specific: If you rely on a generic model, you can watch it conflate “TDP” (Thermal Design Power) with “TDP” (Tax Deferred Pension). Good times. Then your system retrieves the world’s best explanation of an entirely unrelated concept. Yay! We've seen studies where generic RAG failed to answer 81% of questions on financial docs. Ouch.
- Pro tip (kind of): Some folks say, “Just fine-tune the generator, not the retriever!” But from what I’ve seen (and banged my head against), the biggest leaps in domain performance often come from more accurate retrieval. After all, if you can’t find the right data, no fancy LLM “super prompt” is going to save you.
- Fine-Tuning Woes: Sure, you can fine-tune embedding models for your domain, although that means you actually need domain-labeled data. Plus, you get the added joy of babysitting an entire training pipeline. Oh — and let’s not forget that you can’t just simply switch models — you need to reindex and re-embed the data using the new model while still using the old model to retrieve any data that hasn’t been updated.
When Vector Similarity Becomes “Vector Confusion”
So you’ve got embeddings. Naturally, you store them in some vector database, enabling that cosmic “semantic search.” In theory, the chunk that’s most “similar” to your query in high-dimensional space is the best one to answer the question. In practice, it might be full of synonyms and tangential discussions. Great for the user who wants a random treatise on a loosely related concept. Not so great for the CFO, who just needs next quarter’s M&A plan details.
Hybrid Search (keyword + semantic) helps, but now you’re splicing together “BM25 ranking for exact terms” with “neural embeddings for conceptual proximity,” and you end up with a retrieval pipeline that has more configuration knobs than your uncle’s old stereo receiver. Turn the “neural weight” dial too high, your CFO’s M&A question misses the crucial doc because the term “acquisition” was spelled out as “buyout.” Turn it too low, every mention of “acquisition” (including nonsense references to acquiring pets) comes flooding in. Enjoy the debugging slog.
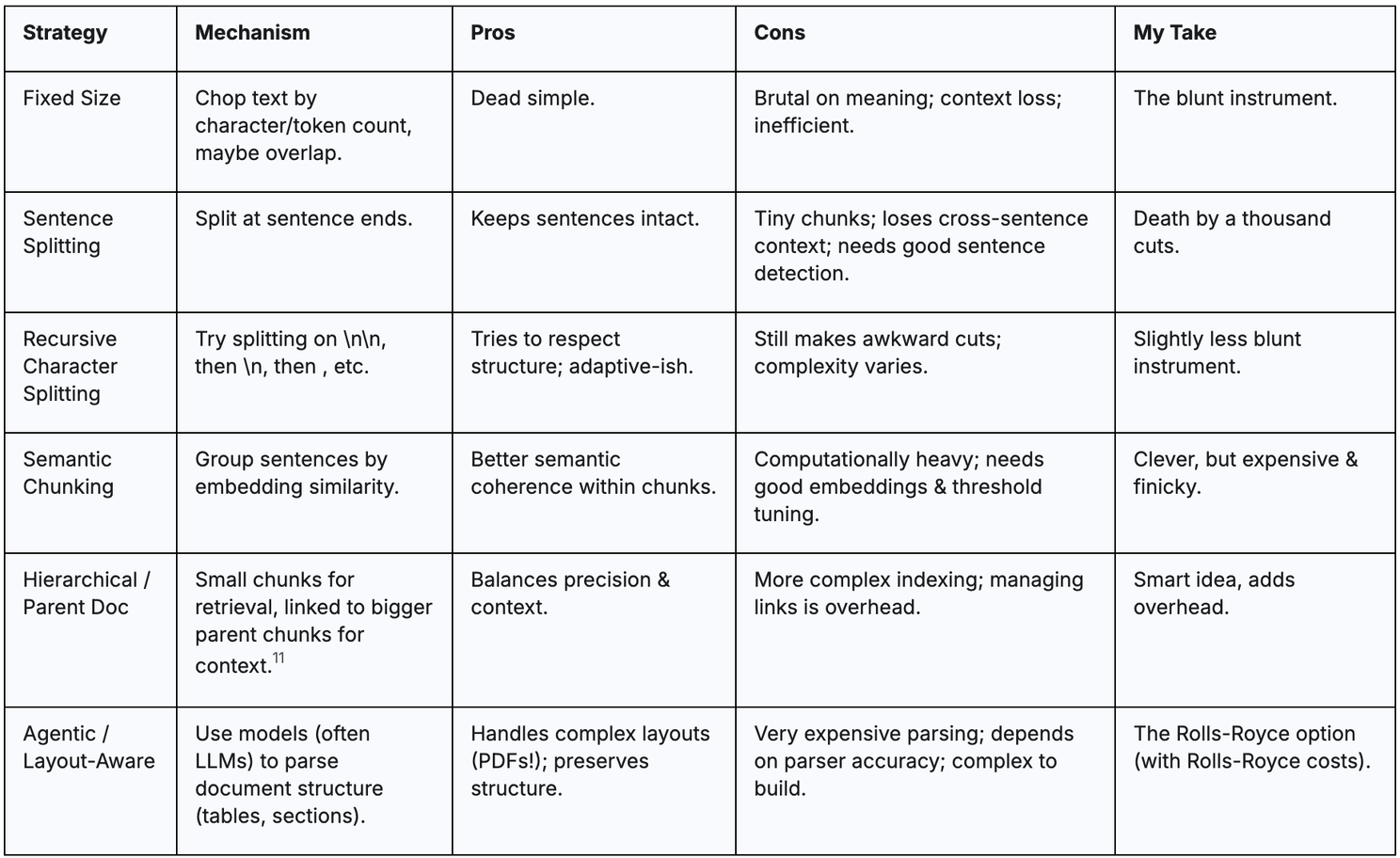
Chunking: It’s the Worst Party Trick in RAG
Splitting documents into “chunks” might sound trivial—until you see your vector store indexing a mid-sentence slice:
“Quarterly revenue… the CFO made a… statement about synergy… next quarter’s bud-”
The system will dutifully retrieve this chunk, leaving the LLM to guess how the story ends.
- Fixed-Size Splits: Just Hack ‘n Hope. Too big? Congratulations, your chunk includes the entire PDF. Yes, you’ll retrieve everything plus the kitchen sink. Good luck extracting that one key figure from among 17 tangential paragraphs. Too small? You end up with single-sentence shards lacking context for the next sentence, leading to the dreaded “I see you have half a fact, care to guess the rest?” problem.
- So-Called “Semantic” or “Layout-Aware” Chunking. In an attempt to be clever, frameworks offer chunking that tries to preserve tables or paragraphs. But if your dataset is messy, you’ll find half your rows get cut because the extraction tool decided “Oh, that must be an empty cell.” And let’s not forget the cost: ironically, you often need a robust pre-processing pipeline — yet another mini-model or script that tries to parse your doc layout before chunking. Because what we needed was more moving parts that could break.
A Quick Look at Chunking Hell
Ambiguity & Multi-Hop: Where Queries Go to Die
Language is ambiguous. RAG systems? Not so much.
Ambiguous Queries: “What is the rate?”
At some point, you’ll see a user ask: “What is the rate?” Meanwhile, your knowledge base has shipping rates, interest rates, pay rates, and reaction rates for a chemical formula. Without context, your RAG system might just say: “Yes.” Or it’ll retrieve a chunk about interest rates in 2019, ignoring the fact that the user is shipping a crate of rubber ducks to Bermuda in 2025.
You could implement query rewriting or clarifying questions. But that either adds latency (multiple LLM calls) or changes your entire user experience. Because “Chatbot that won’t let me finish a question before pestering me for clarifications” is everyone’s dream, right? Vector similarity just isn't built for this kind of logical disambiguation.
Multi-Hop: Because We Needed Extra Steps
A single chunk with the entire answer is easy — like “Who’s the CFO of Acme Inc.?” If it’s stored in one place, you’re golden. But real questions can be: “Which subsidiary of Acme Inc. acquired that obscure startup, and how many employees joined from that deal?” Two different docs, maybe three. Standard RAG tries retrieving them in one go, probably failing to realize it needs multiple passes. Some clever folks do iterative retrieval, or “Agentic RAG,” or strap on a knowledge graph. Boom, complexity times ten.
More Bells, More Whistles, More Headaches
So, you add advanced components to fix the basic problems. Prepare for new problems.
Re-Ranking: E=mc², or Possibly $=ms²
For folks who can’t stand the junk in top-K retrieval results, re-ranking is the next frontier. Cross-encoder or LLM-based scoring can fix the garbage. But keep your wallet handy: re-ranking each candidate chunk is expensive at scale. Unless you have an HPC cluster just sitting around, you might watch your latency triple and your GPU bills skyrocket.
KGs: The Sledgehammer for Relationship Tracking
Nothing says “we care about structured relationships” like building a knowledge graph (KG). Carefully transform your data from raw text into triplets: (Entity A) — [acquired] — (Entity B). Great for multi-hop queries. Great for explicit relationships. Not so great for your dev team.
- You need to parse the data (which is unstructured or partially structured) into a consistent graph.
- You must define a schema. If your domain changes or the structure is incomplete, everything might break.
- Querying the KG from a user’s language still requires translation or interpretive dance.
- It’s like adopting a flamboyant parrot: quite the showpiece when it squawks out a few phrases, but constant feeding, grooming, and vet bills.
The Never-Ending Quest for a Good Prompt (and Aligned Generation)
Turns out, even if your retrieval is perfect, you can still sabotage it all with a subpar prompt. A static prompt template might say “Use the context below to answer the user’s question.” But if that user question is ambiguous, or the retrieved context is 10 pages of legal disclaimers, guess what? The LLM may or may not decide to read it.
Dynamic prompting can help the LLM handle each query with targeted instructions, like “You’re answering a financial question, so be precise.” But building such adaptive logic can feel like writing an entire orchestration engine that basically tries to psychoanalyze the question, the user, and the retrieved text. And yes, more logic means more ways to break.
And here’s the kicker: even with perfect retrieval and a great prompt, the LLM may still generate the wrong kind of answer. It could give you a paragraph when you need a table. This "generation alignment" problem is huge.
Evaluating RAG: The Blind Men and the Elephant
How do you know if your RAG system is actually any good? Good question. Standard metrics often lie.
Typical IR & NLP Metrics: Incomplete at Best
Precision, recall, F1, BLEU, ROUGE—most of these are built for either retrieving the right doc set or matching a “reference” text. RAG is more complicated. You need to measure:
- Retrieval coverage/relevance (Did we get the right stuff?)
- Answer correctness/faithfulness (Did the LLM actually use that stuff correctly without making things up?)
- Generation quality (Is the answer coherent, relevant to the query, concise, helpful?)
- Outcome alignment (Did it give me the table I asked for, or just a rambling paragraph?)
- User satisfaction (Because sometimes the technically “correct” answer is useless or infuriating).
Automated “Faithfulness” Checks (aka Let LLMs Judge Themselves?)
Some newfangled methods have LLMs critique their own or each other’s outputs for hallucinations. Let’s hope the generative model that occasionally dreams up brand-new facts is good at calling itself out. Absolutely no conflict of interest there.
Real talk: if you run an enterprise setup, you’ll want a more robust approach—maybe partial human-in-the-loop or domain-specific checks. But that’s a non-trivial undertaking that can feel like building a second AI system to watch your first AI system.
The Alleged “Dynamism” of RAG (Or Lack Thereof)
RAG is supposed to be dynamic, right? Accessing fresh data? Well...
Feedback? What Feedback?
One of the biggest illusions about RAG is that it’s automatically “up to date” because we can re-index new data. But that says nothing about how the system handles user feedback. Meanwhile, your retrieval pipeline keeps serving stale or suboptimal results.
Data & Concept Drift: The Shifting Sands
Domains aren’t static. A model that understood your product names last quarter might get tripped up next quarter if you rename everything or acquire a new company with weird brand jargon. Drifting data means your carefully orchestrated chunk sizes and domain embeddings might degrade unless you have a plan to retrain or re-chunk.
“Easy RAG” vs. Enterprise Reality: The Framework Facade
Frameworks promise simplicity. Reality delivers complexity.
LangChain & Friends: The Weekend Warrior Toolkit
LangChain is the poster child for “plug-and-play RAG pipelines.” It’s got all these modules, from vector stores to LLM prompts to memory modules. But the defaults are typically naive. It’s great for a weekend hackathon or a quick proof-of-concept. Then Monday morning hits.
Managed Services (e.g., AWS Bedrock KB): Pay More, Still Tinker
You can pay for a fully managed platform that offers everything from ingestion to chunking, hybrid search, knowledge graphs, fancy re-rankers, and “evaluation modules.” Sounds cool, but you’re at the mercy of their defaults and parameter dials.
That’s how you end up with solutions that mostly handle your data, except for that weird doc type or that niche re-ranker you wanted to try. So, basically, you’re back to square one with partial coverage.
Let’s Wrap: The Startlingly Painful, but Fixable, Reality of RAG
So here we are. RAG holds a lot of promise for bridging the gap between generative models’ creative language abilities and the need for real, domain-specific facts. But it’s no silver bullet. The short version?
- Retrieval is still prone to lexical mismatches, ambiguous queries, and domain weirdness.
- Chunking can be a downright fiasco if you don’t tune it carefully.
- Multi-hop queries can blow up a single-pass pipeline.
- Advanced add-ons (re-rankers, knowledge graphs) solve some issues but balloon your system’s complexity and costs.
- Generation alignment is often poor; getting the right facts isn’t enough if the output format/style is wrong.
- Evaluation remains an adventure in “choose your own partial metric.”
- Adaptation is often minimal, so the system’s intelligence is only as fresh as your last manual tweak.
- Enterprise deployment faces hurdles with data complexity, scalability, cost, and integration.
Because let’s face it: if RAG truly “just worked,” I’d be out of a job. Or at least I’d have fewer things to rant about.
Final thought: RAG isn’t hopeless, it’s just complicated. If you’re diving headfirst, embrace that you’re basically building an entire search engine plus a dynamic text generator, plus a dozen extra layers to handle re-ranking, feedback loops, generation alignment, and domain knowledge. If that sounds like a lot, well, it is. But we’re geeks, and we love complexity. Until it breaks on a Friday night, that is.
Happy RAG’ing, and may your vector queries always retrieve the chunk you actually wanted.