Connect
Bring documents, URLs, or raw text into an observable knowledge workflow.
Production infrastructure for domain AI
Connect proprietary knowledge, control context, and deploy cited agents and workflows through the console, APIs, or SDKs—in your cloud or ours.
Bring documents, URLs, or raw text into an observable knowledge workflow.
Control context with hybrid retrieval, reranking, filters, and evidence.
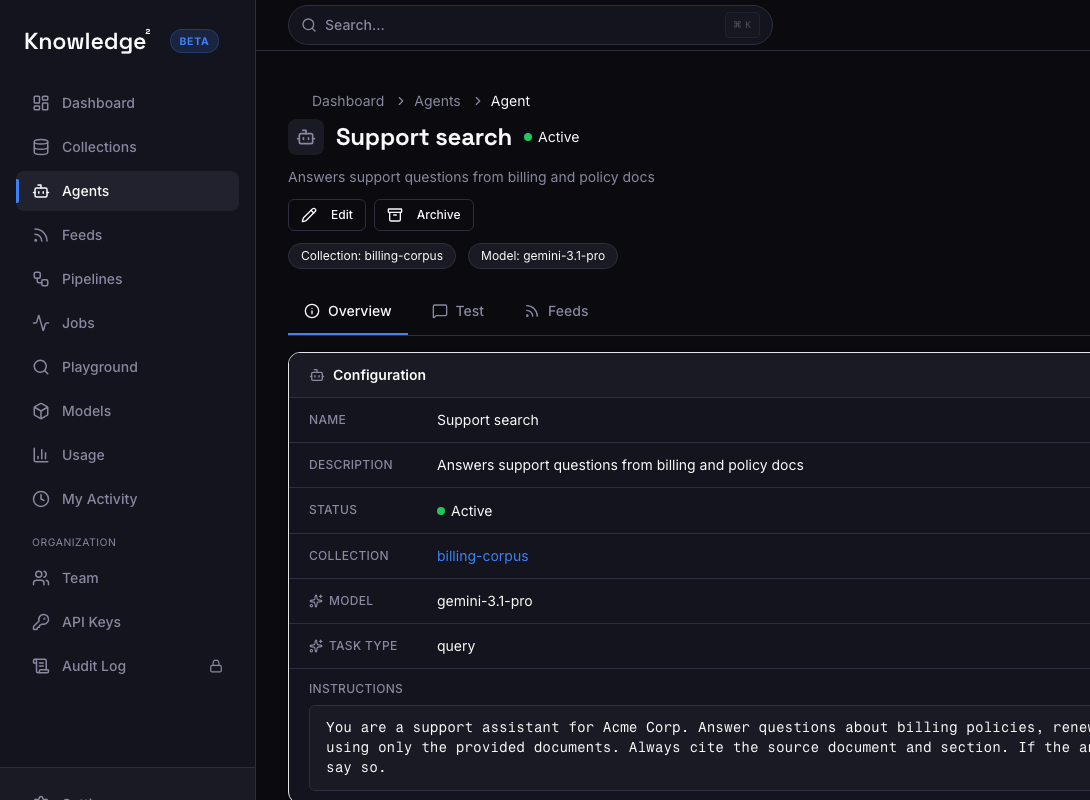
Run cited agents and workflows through the console, APIs, or official SDKs.
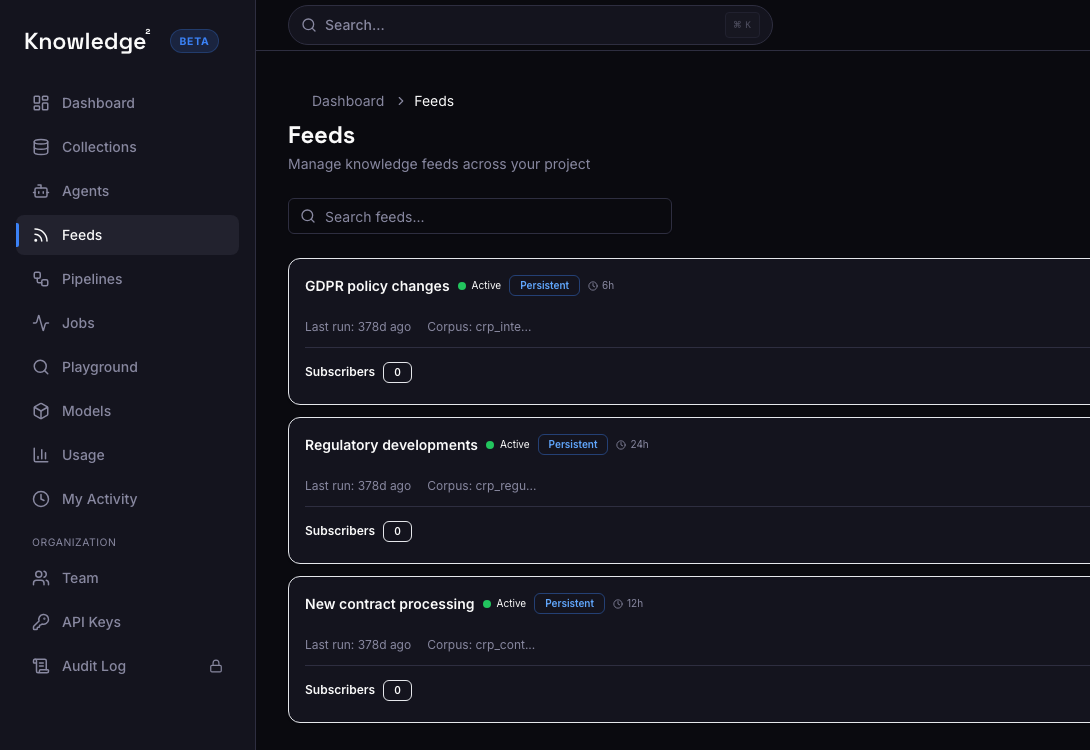
One connected lifecycle
Your document collections and knowledge bases
legal_contracts
Master service agreements, NDAs, and procurement terms.
247 docs
nda_library
Ready92 docs
vendor_agreements
Ready137 docs
compliance_policies
Ready58 docs
Add documents, URLs, or raw text and follow them through ingestion and indexing.
Customers & partners
Our teams explored methods for tackling some of the industry's toughest data challenges:
Opifiny strictly deploys AI capabilities within Opifiny-controlled infrastructure.
“With Knowledge², our customers go from scoping to a working proof-of-concept in minutes, not weeks. Their technical and business teams move in lockstep instead of stalling on infrastructure. The ability to deploy within regions that have strict data residency requirements removes the last blocker to adoption.”
“Knowledge² lets us swap the underlying LLM on any agent without touching the retrieval layer or application code. We benchmark models side by side on real customer data and ship the best fit, per workflow, in the same afternoon.”
For developers
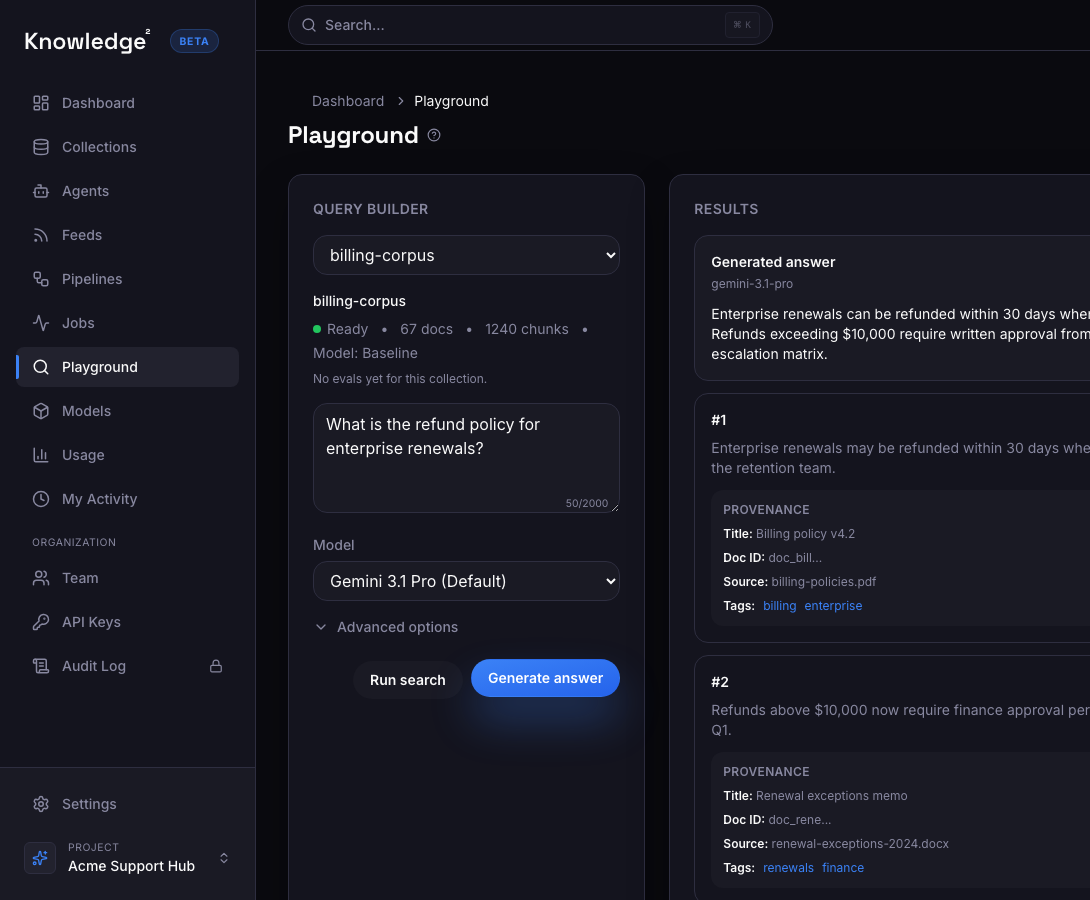
Connect real source material, generate a grounded answer, inspect the evidence, and decide whether it is ready to ship.
Create a corpus, ingest documents, build indexes, and search.
1# pip install knowledge22from sdk import Knowledge234client = Knowledge2(api_key="k2_...")5project = client.create_project("Site Expert")6corpus = client.create_corpus(project["id"], "Product Docs")78client.upload_documents_batch_and_wait(9 corpus["id"],10 [11 {12 "source_uri": "doc://security",13 "raw_text": "Rotate API keys from Settings > Security.",14 },15 ],16 auto_index=False,17)18client.sync_indexes(corpus["id"], wait=True)1920results = client.search(21 corpus["id"],22 "How do I rotate an API key?",23 top_k=5,24 return_config={"include_text": True},25)26print(results["results"])Knowledge² controls what the model can see, keeps the supporting evidence visible, and gives teams a practical path to deployment.
Pricing
For developers evaluating grounded retrieval and agents.
$187 / mo, billed annually
For teams shipping domain-grounded AI workflows.
For private deployment, enterprise controls, and rollout support.
Cited answers. Controlled context. A clear path from evaluation to production.