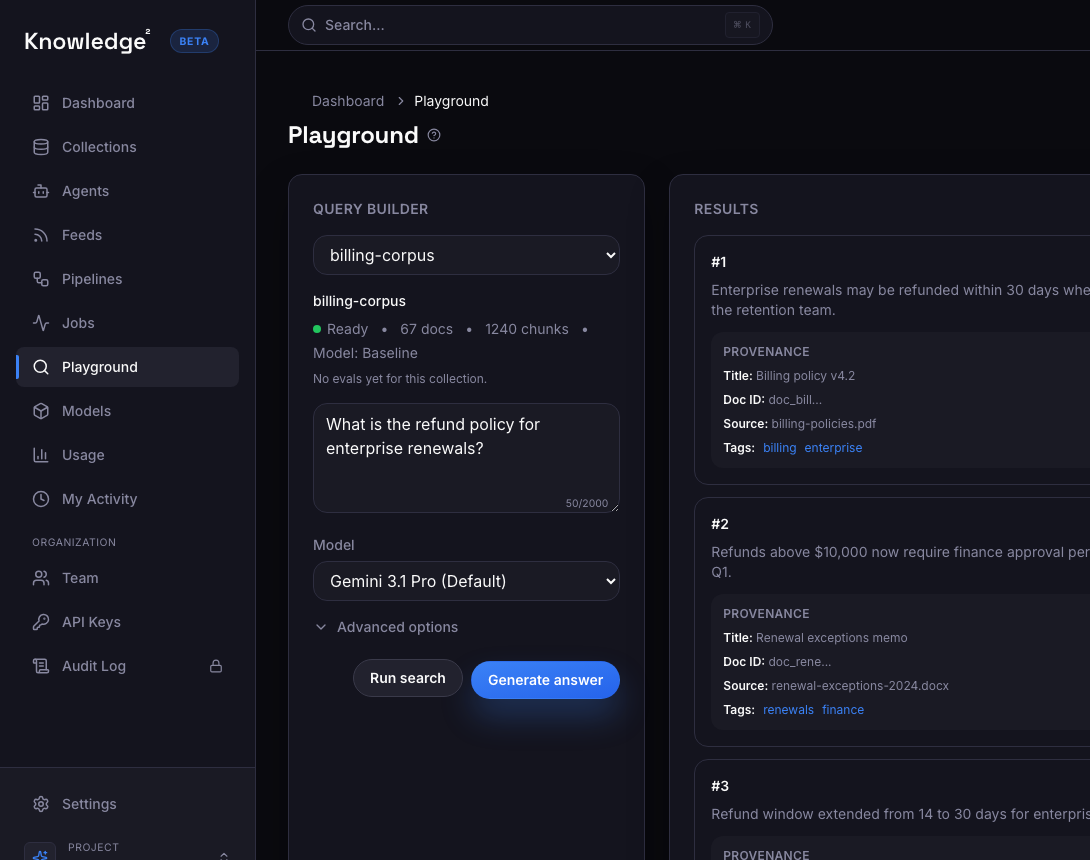
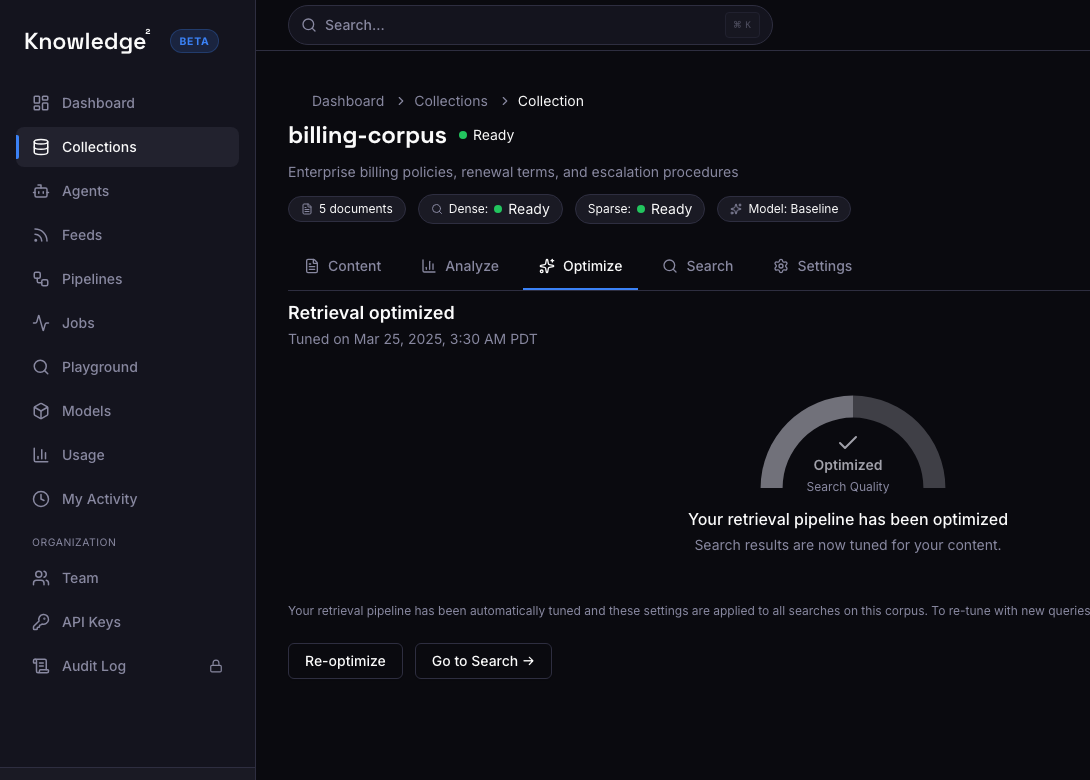
Example advanced workflow
A search team tunes for a harder query set instead of stopping at baseline relevance
The platform can support deeper quality work once the first experience is already shipping.
Objective
Improve relevance on relationship-heavy policy questions
Optimization outcome
The team starts a tuning run on real evaluation data, compares it to the current baseline, and only promotes the change if quality improves.
- Baseline checked before promotion
- Run status visible to operators
- No separate tooling required